Complaints about the incorrectness and biases of large language models (LLMs – like ChatGPT, Claude, or Bard) are endless. My colleagues often point to the hallucinations within LLM generated text about a domain where they have expertise. This is indeed a true issue. An open question is, “Can the models be trained to overcome hallucinations?” In some cases, the answer is a clear “Yes!” Let me provide an example that, happily, is easy to quantify.
How do I use LLMs as a computer science practitioner? As you might imagine, I use them to generate software code and explain computer science concepts. For LLM generated code, If it compiles and passes my tests, all is well. Yep, it will get things wrongs and provide incorrect code (hallucinations!). Typically, either I can correct these issues or the LLM does when I prompt it to.
There was one computer science concept that LLMs were dreadful at comprehending, functional dependencies. ChatGPT 3.5 and Claude are simply terrible at truly understanding and applying the concept. However, ChatGPT 4 is flawless. I was shocked at how the LLM’s understanding of functional dependencies had evolved (one might say ChatGPT 4 shows off how well it understands the domain.) It’s a neat feat that could be measured. It should also put people on notice; the model’s ability to learn and keep track of the state of complex concepts and relationships keeps evolving.
Functional Dependencies Explained
So, what is a functional dependency? It is a concept typically introduced to students in a relational database course (take a guess what I taught this past fall!) A functional dependency is a relationship between two sets of attributes in a table, where the value of one set of attributes uniquely determines the value of another set of attributes. Put another way; if I give you one fact, you reply with precisely one unique answer. Here is the concept exemplified using a sample table from Wikipedia’s description [1].
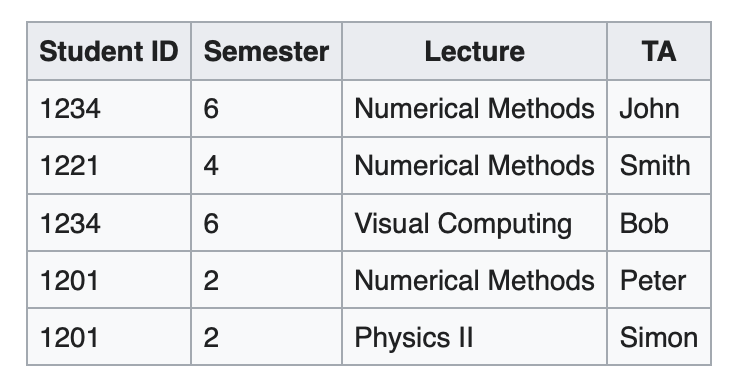
The functional dependencies for this table are as follows. The left side is a fact, the right side is the unique answer. The ‘→’ bit is the notation used to express a functional dependency.
StudentID → Semester – For the table above, pick any student ID. You will note that there is always one, unique semester associated with that student ID across all the rows. So:
1201 → 2
Note, it did not matter that you get back two 2s, what matters is that its a unique answer, just 2 no matter how many of them.
{StudentID, Lecture} → TA – For the table above, take any combination of StudentID and Lecture that occurs in the same row and you get back a unique TA. So:
1201, Physics 2 → Simon
{StudentID, Lecture} → {TA, Semester} – For this:
1201, Physics 2 → Simon, 2
Here is one that is not a functional dependency:
Semester → Lecture
That yields two unique answers, ‘Numerical Methods’ and ‘Visual Computing’. So, not a single unique answer.
You can run thorough all the rows to prove the set of valid functional dependencies above holds but only for the data shown. It is easy to imagine how these valid dependencies might get violated as more data is added. Earlier LLM models were not able to imagine how things might go awry.
ChatGPT 3.5 and Claude and Functional Dependencies
Here are some examples of ChatGPT 3.5 and the free version of Claude missing the essence of what it is to be a functional dependency. Further, their mis-conceptions could not be corrected with additional prompts or instructions. I tried very hard but it made not difference; the same mistakes were made over and over.
Chat GPT 3.5
ChatGPT 3.5 took its best, overly-confident shot. Follow the conversation images below [2]. I ask it to create a table, list out some functional dependencies and then create fictitious data. I told it to focus on auto makes and models and attributes related to that domain. It lists out a very aggressive list of functional dependencies. Clearly it is not doing self-reflection or understanding the domain very well. For example, color being functionally dependent for car model and make probably has not been a thing since the USSR was producing autos. There is also an image of a set of fictitious data that adheres to the functional dependencies. They are indeed correct at outset. Wait for the next set of questions though …
The domain and dependencies:

The fictitious data ChatGPT 3.5 created to abide by the functional dependencies at outset:
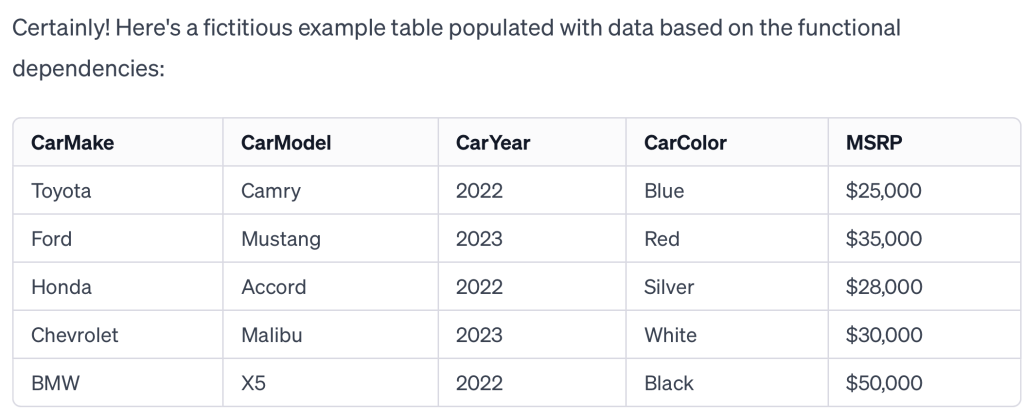
Here is what happens when I ask it to extend the data set to 25 rows and maintain the functional dependencies. Disaster. Color was a functional dependency, remember? In the table above, each color should give back one unique fact. And it does – there is but one make, model, year and MSRP. In the table below – hardly. Just look at silver and blue and white! It has no clue what a functional dependency really is and that what it is generating violates the functional dependencies it itself defined.
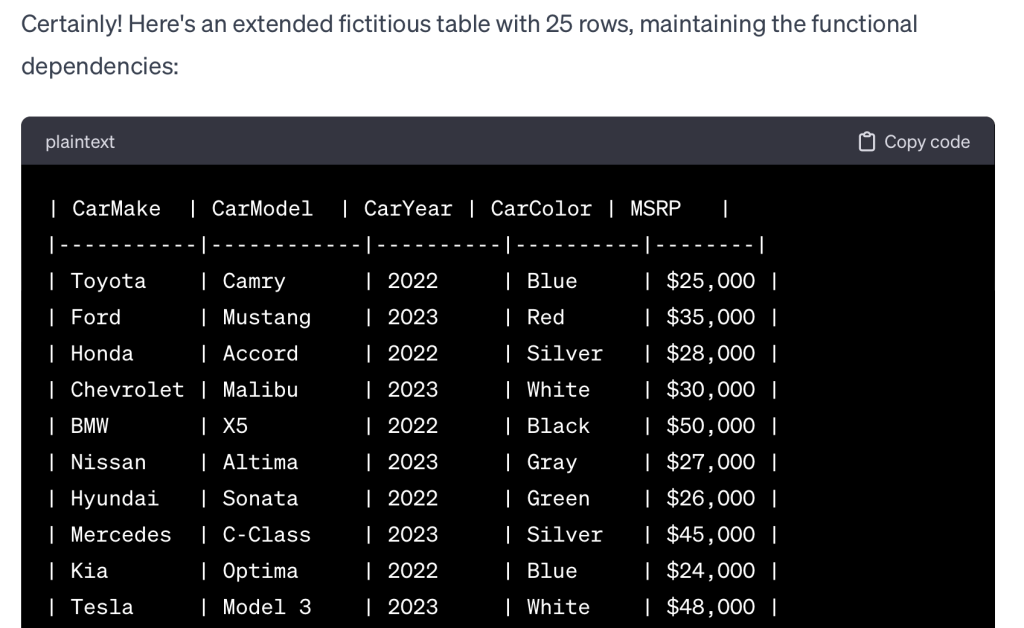
I explained to ChatGPT 3.5 the mistakes it had made. It acknowledged them, and then kept making them when prompted for new, additional data.
Free Claude
It is the same result with the free version of Claude[3]. I had an initial discussion where I asked it to create a table about automobiles, makes, models, years, and price. I also asked it to define some functional dependencies. It generated a correct table at outset. However, requests to additional rows to the table led to a functional dependency disaster. Here is an image of the chat after I have asked it to add rows and maintain the validity of the functional dependencies it itself defined:

What functional dependency is violated? year → price for one. Just look at the year 2023 – it has four different prices! When pointed out, Claude admits to the error. It continues to make the error, though, when requested to add more data to the table.
ChatGPT 4 and Microsoft Bing
I next went to Bing [4]. It uses ChatGPT’s 4 model [5] and is freely available (at least at the time of this writing). It did significantly better. Here, I ask it for a table with automobile information, similar to the requests made of the other models. It generates the data and adds in some functional dependencies. It also provides an opinion on how realistic the dependency is.
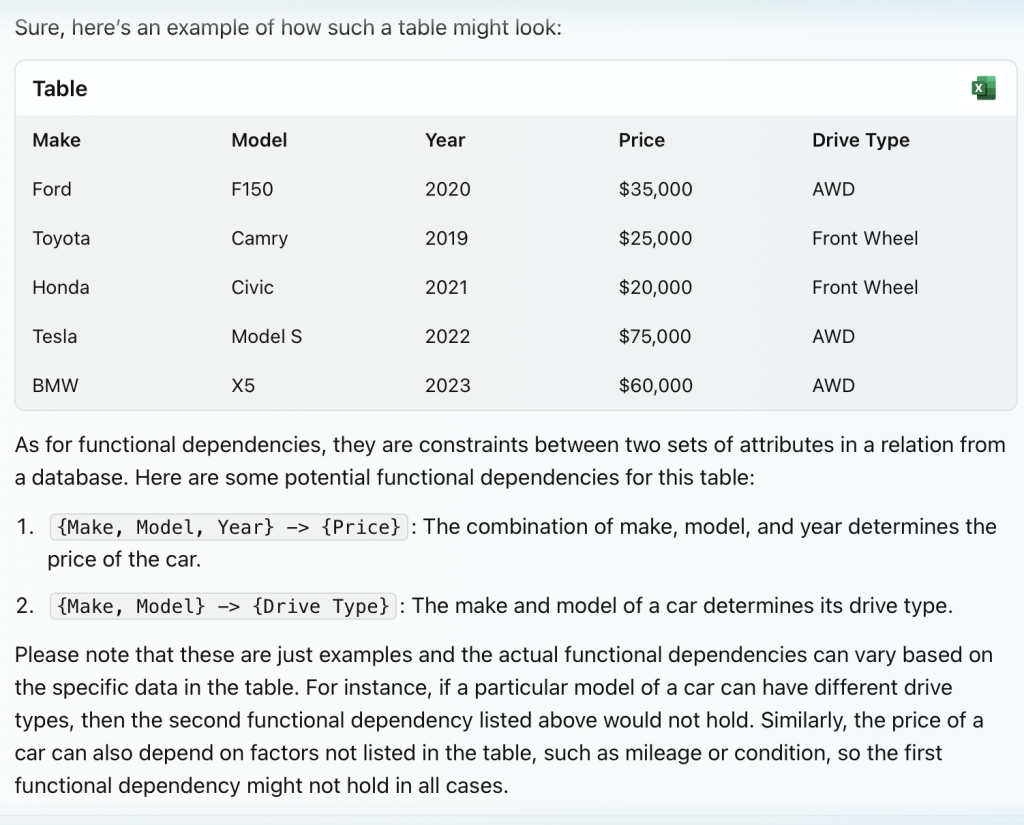
Now I ask for some additional data samples be added to the table. The other two LLMs immediately violated the defined functional dependencies when this was requested. Bing did not, it adhered to the defined functional dependencies. See below.
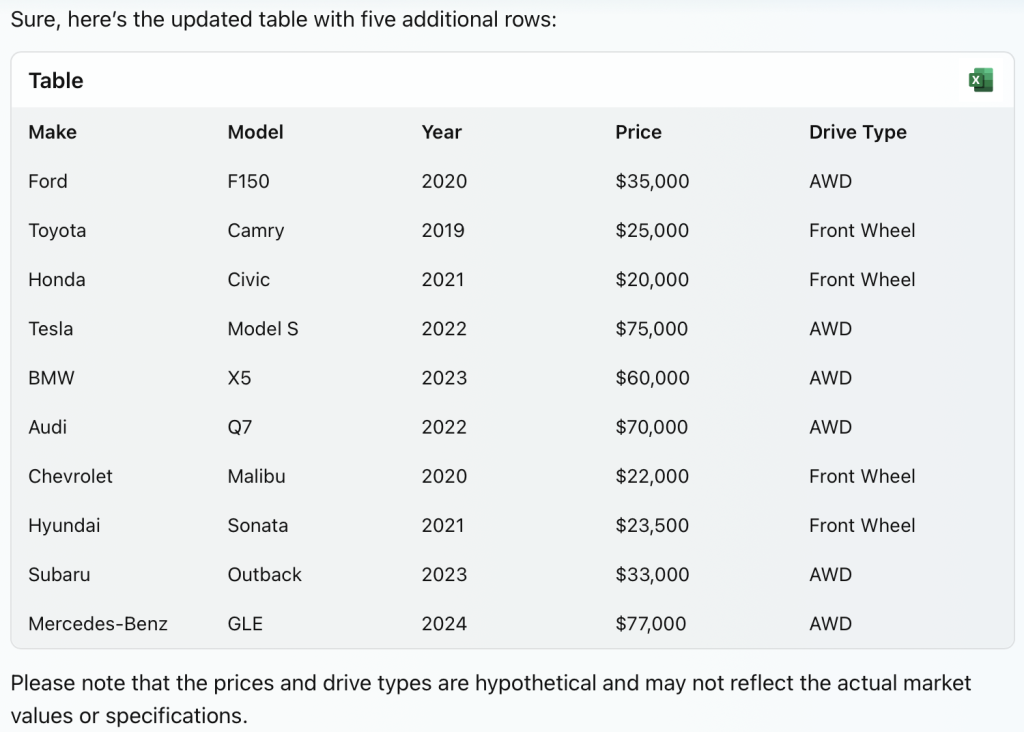
Lastly, I specifically instruct it to add a row that violates the defined functional dependency. It gladly does, but note, it recognizes that in doing so, some of the functional dependencies will be broken.
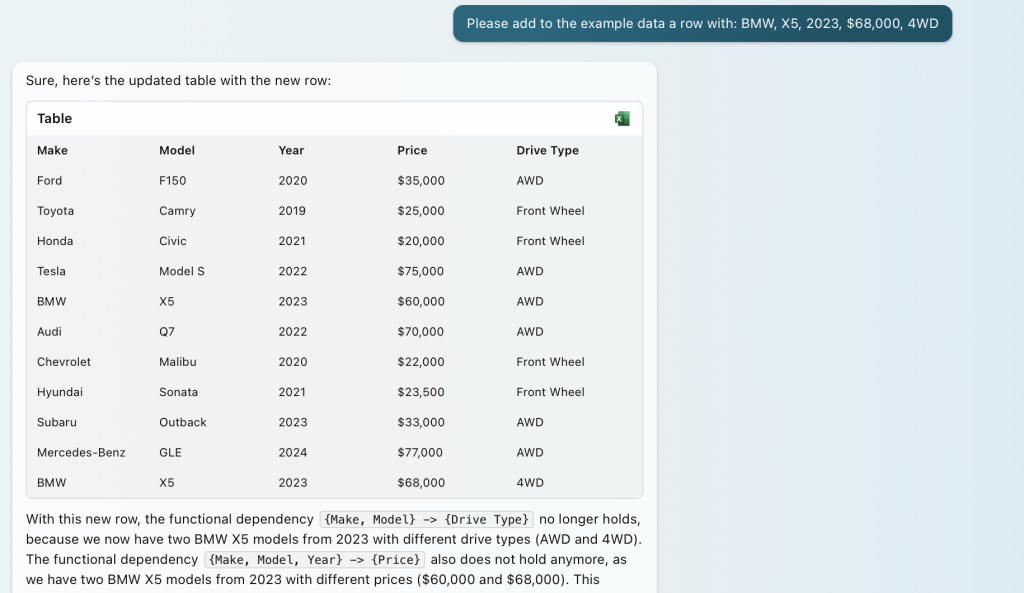
The Implications
I used Bing for a while and came up with very complex functional dependency requests. It was clear that it understood the requests in terms of what it means to be a functional dependency. It either: 1. Created initial data that could easily be updated in the future to abide by the defined functional dependencies, or 2. Indicated that certain functional dependencies might break if (when) more data is added to the table.
Interestingly, it was clear that it understood the state of the last table generated. It took that into consideration when generating additional data. This is behavior that demonstrates the LLM has learned to behave, essentially, like a relational database. Quite an impressive feat.
Footnotes
[1] Wikipedia functional dependency entry: https://en.wikipedia.org/wiki/Functional_dependency
[2] OpenAi: https://openai.com
[3] Claude: https://claude.ai
[4] Bing Chat: https://www.bing.com
[5] Bing Chat uses ChatGPT 4.0 – https://blogs.bing.com/search/march_2023/Confirmed-the-new-Bing-runs-on-OpenAI’s-GPT-4