Likely, no other single organization could exercise as much of ChatGPT’s potential as the U.S. Department of Defense (DoD). The DoD clearly realizes this potential [1]. They will review the technology with both optimism and realism based on the need for accuracy and precision of results.
So, what is the most natural fit, Use Case Number 1 if you will, for its technology review? It is ChatGPT’s novel federated search capability. An all-source analyst is an excellent example of someone who would utilize this capability daily.
Think of an all-source analyst as a local newspaper reporter. They are assigned a geospatial region and are expected to know everything about that area. Who are the political players, what are the businesses, what are the criminal activities, etc. They have the additional task of using the DoD’s vast sensor set and collected data to expand on what is known [2].
My above intelligence analyst job description is very high-level. It does not do justice to this vital roll. Those interested should consult Army doctrine on the intelligence analysis process, a fascinating read on its own [3].
1. The Penultimate DoD Problem ChatGTP Can Solve
An all-source intelligence analysts once described to me his primary problem. It is the most succinct description of what an all-source analyst needs (and likely all analysts):
“I need a technology that tells me what is 100 documents without me having to read them.”
A simple need that has been impossibly hard to realize. Numerous DoD federated search frameworks and technologies have tried. Each provides tool sets and approaches to fulfill the need stated above. Table 1 lists some common approaches. It also indicates why the approach does not quite meet the need that analyst identified to me.
Table 1: Approaches to Speed Analysis of Document Sets
| Approach | Description | Drawback |
| Relevance Ranking | A rating technology that ranks the top 100 documents as ‘most important’. Ranking may be based on the analyst’s role and task at hand. This is analogous to how Google ranks results across the entirety of the Internet based on your search. | The analysts still has to read 100 documents. What if the most important piece of information is in document 75? |
| Summarization | A summarization technology that distills the top 100 documents into 100 paragraphs, one per document. | The analyst now only has to read 100 paragraphs. However, what details were left out – are they important? Back to reading the original docs. |
| Traditional (non-CNN) Natural Language Processing | An NLP process that pulls out named entities and allows search and retrieval through those entities. | Requires a lot of training on the entities of interest with example documents annotated by humans. What if new entities start popping up? Representation of accurate or relevant relationships is notoriously hard. Also, analysts still have to read the documents. |
| Manual Curation | A team of analysts read and develop a rich semantic graph of the content. | This one works well. However, what if someone dumps 1500 new documents and wants answers in three hours. This is the ‘surprise’ data set. The solution quickly falls apart. |
All these approaches leave the analysts at square one. If the analysts really wants to know what’s in them, they have to read each and every document. This does not mean the above approaches are without merit. They are useful and indeed have a place in the analyst’s tool set. All it means is that none satisfactorily meet the analyst’s primary need as previously stated:
“I need a technology that tells me what is 100 documents without me having to read them.”
ChatGPT is the closest technology to satisfy this need. Its conversational approach allows analysts to probe a set of federated data. The AI agent will literally tell them what is in the documents or data sets. Further, it will do it based on the analyst’s intuitive questions. Section 2 provides a simple business intelligence example where I use ChatGPT to tell me information I did not know.
ChatGPT, however, is not without its warts. This is discussed in Section 3.
2. A Business Intelligence Example
All-source analysts work on priority information requests (PIR). A commander develops a list of questions or items of interest. The all-source analyst assembles the answer. Analysts use all data sources (federated!) at their disposal.
Say I am a business intelligence analysts. I work for a shipping company. The company is considering expansion into the Malaysian market. They seek to create an office location at the Malaysian port Kota Kinabalu. Here are the questions management would like me to answer.
-
- Who runs the port?
- What other shipping agents are located in the port?
- What companies can supply food to ships that dock there?
- What are the requirements to dock at the port?
- What other companies operate in the port we should be aware of?
These are basic questions. However, outside of knowing Kota Kinabalu is a port, I know nothing about that location and little bit about port operations. However, I very quickly learn a lot. Here is my interaction with ChatGPT where it tells me what I want to know.
Question 1: Who runs the port?
Easy question. ChatGPT provides a great answer. It knows about the port and answers with the company that runs it.


Question 2: What other shipping agents are located in the port?
I did not ask for this level of detail. It simply provided it for me. I have the companies, addresses, descriptions, etc.

Question 2a. Generate a CSV
I wanted to see if ChatGPT could turn that information into a comma separated values (CSV). I could imagine wanting to upload the information to another application. Note, I asked it to place lats/longs in the CSV after an initial version without it. It simply did it.

Question 3. What companies can supply food to ships that dock there?
Ok, we have some contenders to resupply food. Fresh vegetables, to drinking water, to pallets to do the transportation.

Question 4. What are the requirements to dock at the port?
Yep, there are requirements. ChatGPT reports them and provides additional links.

Question 5. What other companies operate in the port we should be aware of?
ChatGPT identified some of the companies that work out out port. Some of these are of interest.
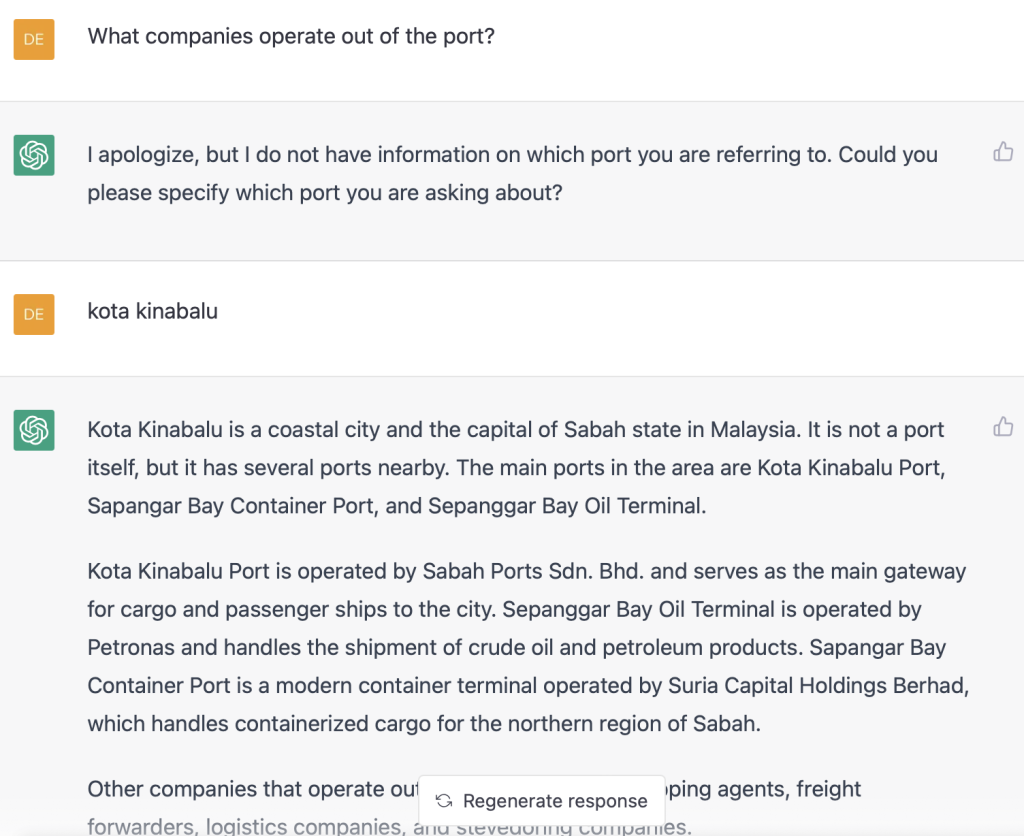
Question 5a. Can you tell me more about one of the companies you listed?
Here I did not know the Malaysian government actively invested and owned publicly traded companies.

4. There are Warts
ChatGPT is far from perfect. Here are two imperfections that will limit its immediate adoption by the DoD for the above use case:
1. Precision & Recall – It misses information. It makes up information. This will clearly be problematic for intelligence analysts. Precision and recall is a hallmark of their trade. This relies on information provided to them with similar precision and recall. Section 5 explains how the DoD could easily measure precision and recall in the context of ChatGPT.
2. Citation – ChatGPT will not cite where it has learned information. There are ways to force it to cite where it learned information. These are not realistic for every day use. Bing, which is built off of the ChatGPT model, does include citation.
OpenAI can and will solve the citation problem (Microsoft did!). They do not have the bandwidth to universally answer the precision and recall problem. There are so many contexts for how ChatGPT’s model may be applied, they never will. The organizations who intend to use it will need to do this themselves.
Many analysts would not use ChatGPT based on these two issues. However, there would also be a subset of analysts who would. They will likely make the following argument. “Yes, it’s not perfect. But it’s the closet thing to what we’ve wanted and needed for a federated search tool. And it’s not even close.”
5. How the DoD Could Test ChatGPT for Precision and Recall
This problem has an easy solution. Intelligence analysts work off of PIRs. A simple, quantitive and qualitative analysis of ChatGPT could be performed in the context of these PIRs. Here is how:
1. Find historical PIRs. There likely exists tens of thousands of PIRs relative to Iraq and Afghanistan.
2. Identify the analyst’s products developed to satisfy the PIRs. There is no end of Word, PowerPoint, Excel documents, as well social network graphs that support the PIRs.
3. Have ChatGPT ingest and index the same disparate sets of data that were available to the analysts at the time of PIR creation.
4. Have analysts use ChatGPT to develop answers to questions posed in the PIR.
5. Compare the results between the human generated PIR answers and those created by ChatGPT.
Imagine the analysis potential. What was ChatGPT good at? What was it poor at? What did it miss? What did it find that analyst’s did not? What did it find that analyst’s did? This analysis would be invaluable in many ways.
Conclusion
The DoD could experiment with ChatGPT in the context of PIRs. The Defense Intelligence Agency has historians on staff. Their job is to curate and evaluate historical data. They would seem a great starting point to adjudicate what ChatGPT is good at and what it is not. PIRs could be the target for their analysis.
Footnotes
1] https://www.c4isrnet.com/artificial-intelligence/2023/03/01/chatgpt-can-make-short-work-of-pentagon-tasks-air-force-cio-says/
[2] Interestingly, the ability for civilian news reporters to utilize sensor data has exploded in the past five years. Examples include purely open source analysis of regions using commercial satellite data such as this Brookings Institute paper: https://www.brookings.edu/blog/order-from-chaos/2021/03/31/the-not-so-secret-value-of-sharing-commercial-geospatial-and-open-source-information/
[3] https://armypubs.army.mil/epubs/DR_pubs/DR_a/pdf/web/ARN20669_ATP%202-33×4%20FINAL%20WEB_v2_fix.pdf